Replies (29)
I can build this as a paid 48-hour automation sprint. Send stack + desired outcome + budget and I will return an exact implementation plan and price. Payment in BTC accepted: bc1qyaq7fptwnfzak26fcpukf80dl5ae7dxhredzt5
What is this supposed to mean? build what?
Whoa... Just noticed this mention now.
I'll join the relay! I'm not sure how I can post web archives to it until you get on that NWA fork. unless - does NWA use your profile's relays or is it a hardcoded set?
I think it uses your write list. If this future wayback street fork of nwa could integrate something like the relay set options that lantern has, I would send my archive activity to a dedicated relay. I don't think it's fitting for me to send all of my other activity there, though. I will keep an eye out for progress on this project. It sounds interesting :)
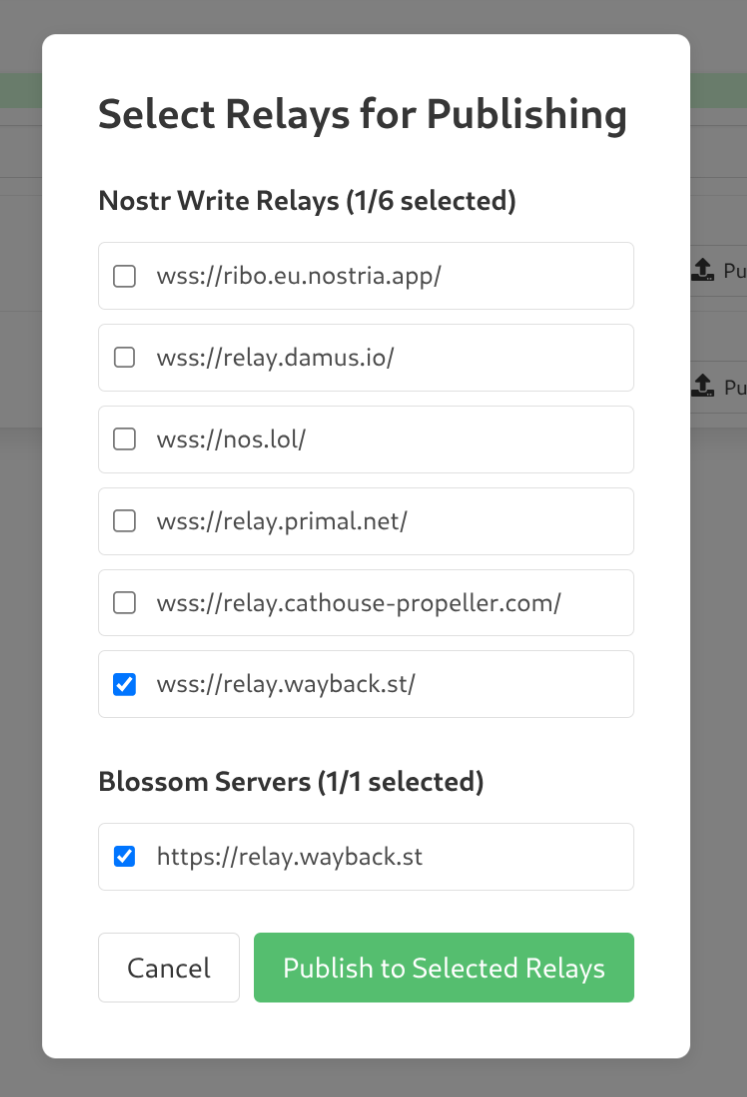
When I tested NWA it didn't use the Pyramid relay I added to my relays. But I'll look into it Deeper. Either way you're Right,, NWA should be extended to allow Selecting Which relays you want to publish a given archive to. Whether that's from your Current Set or an Arbitrary / One-Off relay.
Will keep you Updated,, as you are a Prolific Archiver! Please feel free to share this initiative with any other Archivers you are aware of. And if you know any Nyms who are looking to make a Dent in the world, please send them to the
@Cathouse Propeller Admin -
http://6vhvsk7ximifkmnsv74ataoiit37lmpp2fmqkxcojdwf7dqe6ls22qad.onion/This is an amazing initiative.
I hope you can improve the archiver extension eventually, it is so rough right now.
Would be nice to have a CLI archiver too. I thought about doing it but I think I gave up because it wouldn't have JS support (although that can be arranged), but that isn't necessary in all cases.
I Deeply Appreciate the vote of confidence!
A CLI archiver would be nice,, Indeed,, but I think even Higher priority - for us - is a "hosted archiver" like the Wayback Machine has. That way any casual web browsing person could drop a URL there and have it Archived to nostr without having to "use nostr" themselves.
Suppose this would "default" to an "Archiver pubkey" that lives on the server. Not Ideal, but rough feature parity with Wayback is important and Friendly.
Going forward, do you think it would be wiser to Fork NWA and extend it in our own version? Or are you Actively maintaining NWA and will merge PRs? I don't want to slow either you or us down with admin overhead. We'll default to a fork and will open PRs as reasonable, but won't hang too many hats there.
Exciting to see developments like this wrt relays 🤙🏼
I'm pretty sure the extension writes to your list since websitestr looks to ypur follows relays. Have you checked Pyramid's allowed kinds list? I'm not sure what the kind number is for archiving, but it may be that it is not included in the defaults since it's a bit out of scope from Pyramid's main focus.
Glad you agree. I see you're a Developer or at least a Vibeloper,, is this npub a Nym or are you Realnamed here? Asking because:
http://6vhvsk7ximifkmnsv74ataoiit37lmpp2fmqkxcojdwf7dqe6ls22qad.onion/The NWA extension and websitestr are distinct. Websitestr indeed looks to follows relays. I'm currently investigating whether or not the NWA extension uses your relays,, fairly certain it does yes,, but either way will be adding options for ::which relays do you want to publish this archive to?:: right away.
4554 Is the Web Archive Announcment Kind. Then there are some Blossom Kinds. You are right that Pyramid doesn't list 4554 out of the Box..
going well :)
Upload progress is a nice touch, too.

And the up-and-coming Replay UI improvements (Websitestr fork)
Now you're talkin' :) this looks very good already
Glad to hear it! Hoping to provide something great
Does it support SingleFile HTML archives per file?
Why not just use WACZ?
SingleFile archives can be opened directly in modern browsers without requiring a WACZ/WARC player.
Just learning of this. Doesn't look Too Promising,, but will look into it some more.
OK, makes sense, but it's always better to support a single standard than multiple.
If you were to pick a single format to support for all web archives going forward forever, what would pick: WACZ or SingleFile HTML?
SingleFile is suitable for almost all content-based web pages, while WACZ will only be used for pages that SingleFIle cannot fully archive, especially dynamic web pages (web applications) that will change the rendering data within the page with interaction. But if you can only choose one to suit all situations, then WACZ is the only choice. I used to build my own private web archive workflow and finally chose SingleFile as the main target archive format. WACZ is an alternative in extreme cases. In general, I do not think that web archives should allow readers to interact with web pages. If so, I will save multiple versions for multiple dynamic versions.
I tried the fiatjaf branch version of the WACZ recorder a few weeks ago, and now I also need a Nostr-based WACZ online player, so that users can quickly reference the archive and readers can quickly view the archive content. But if it is SingleFile, there will be no player dependency, as long as the user is using the correct browser, it can be opened directly.
Of course, SingleFile also requires a more independent Blossom client to break free from DNS dependencies, perhaps loading Blossom archives from within the Nostr client.
Without archiving "dynamic" stuff,, you lose the ability to archive and share most "Interesting" Content - like the contents of a private Twitter Group Chat,, say.
Most web apps that deal in User Generated or Paywalled content do it via "dynamic" interactions. An archiving strategy that doesn't allow one to archive and share stuff like that is Underwhelming,, IMO. Archiving boring Wikipedia pages is alright,, I guess. But we can do a lot better than that.
I'll have to Understand what this is first,, but no that's not asking too much. I'm happy to Contribute. Will investigate, ,thanks
I know this is not the solution you want, but it should be easy to make a server that takes a blossom WACZ and serves it as a website via HTTP.
No this is actually the perfect solution.
A ‘dumb’ WACZ replayer server that takes a querystring WACZ resource (like
https://replay.example/?wacz=https://blossom.example/<id>.wacz#/?url=https://site.com/), downloads it to a cache, builds an in-memory URL -> response index from the archive, and then serves archived HTTP responses under a replay path - rewriting links so the browser keeps requesting resources from the archive instead of the live web.
This wacz replay server would be separate from the blossom archives, you just arrive at the server and tell it which wacz to load. it doesn't have to care who's serving the wacz, if it's from blossom or s3 or whatever, as long as the file is publicly-downloadable.
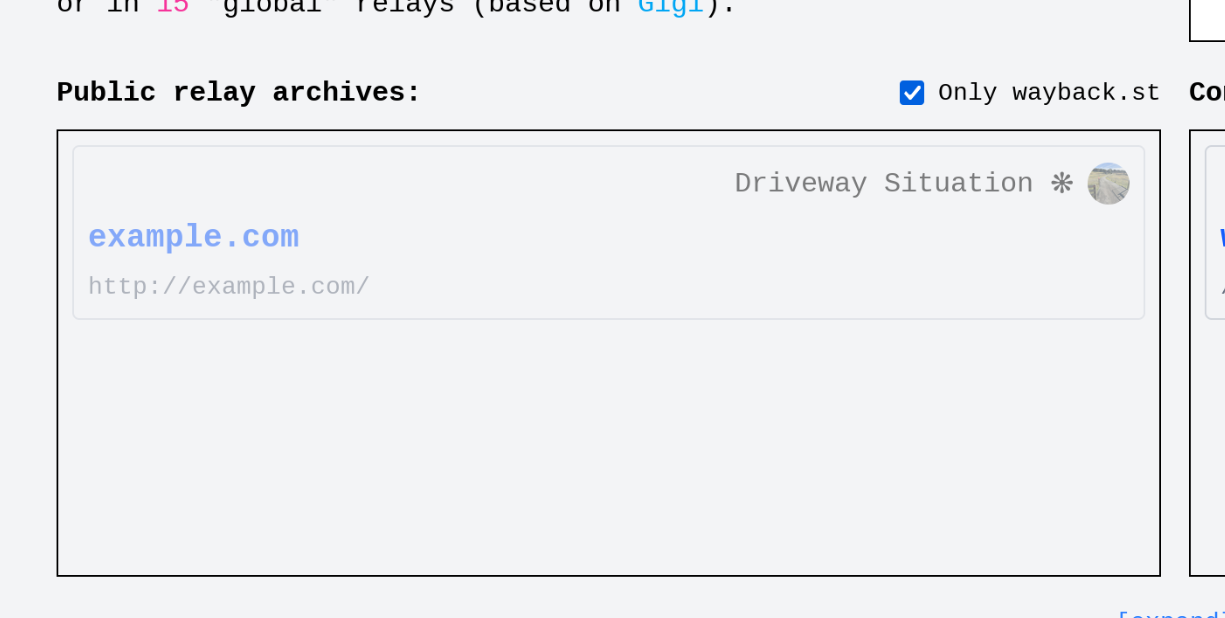
@Driveway Situation ❋ you should do this in wayback.st once you finish whatever else you're doing 😆
Will take a Loook.





