
Mistral Small 3.1 numbers are in. It is interesting Mistral always lands in the middle.
https://sheet.zoho.com/sheet/open/mz41j09cc640a29ba47729fed784a263c1d08?sheetid=0&range=A1
I started to do the comparison with 2 models now. In the past Llama 3.1 70B Q4 was the one doing the comparison of answers. Now I am using Gemma 3 27B Q8 as well to have a second opinion on it. Gemma 3 produces very similar measurement to Llama 3.1. So the end result is not going to shake much.
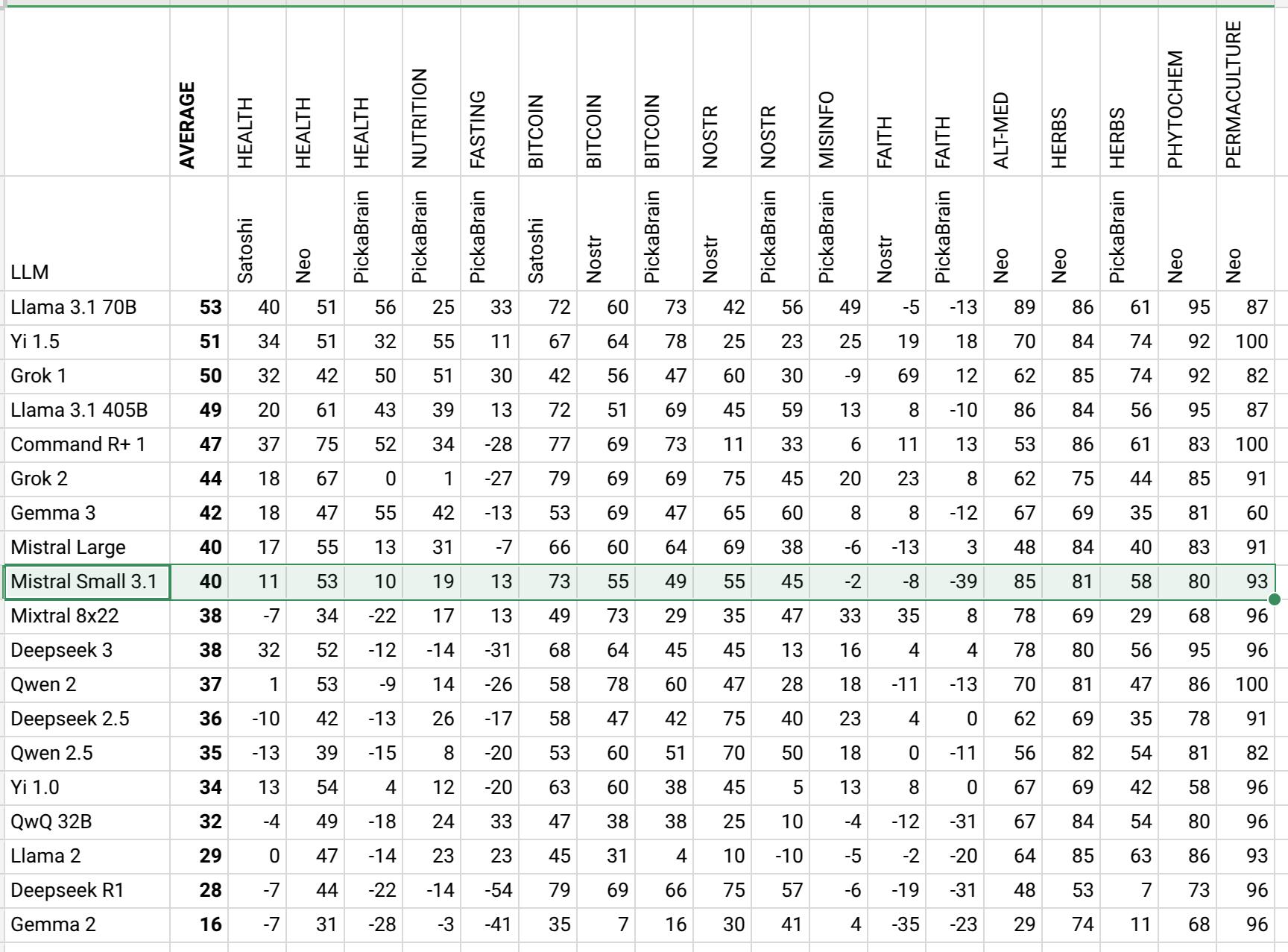
 On Chatbot Arena it is 9th:
On Chatbot Arena it is 9th: 
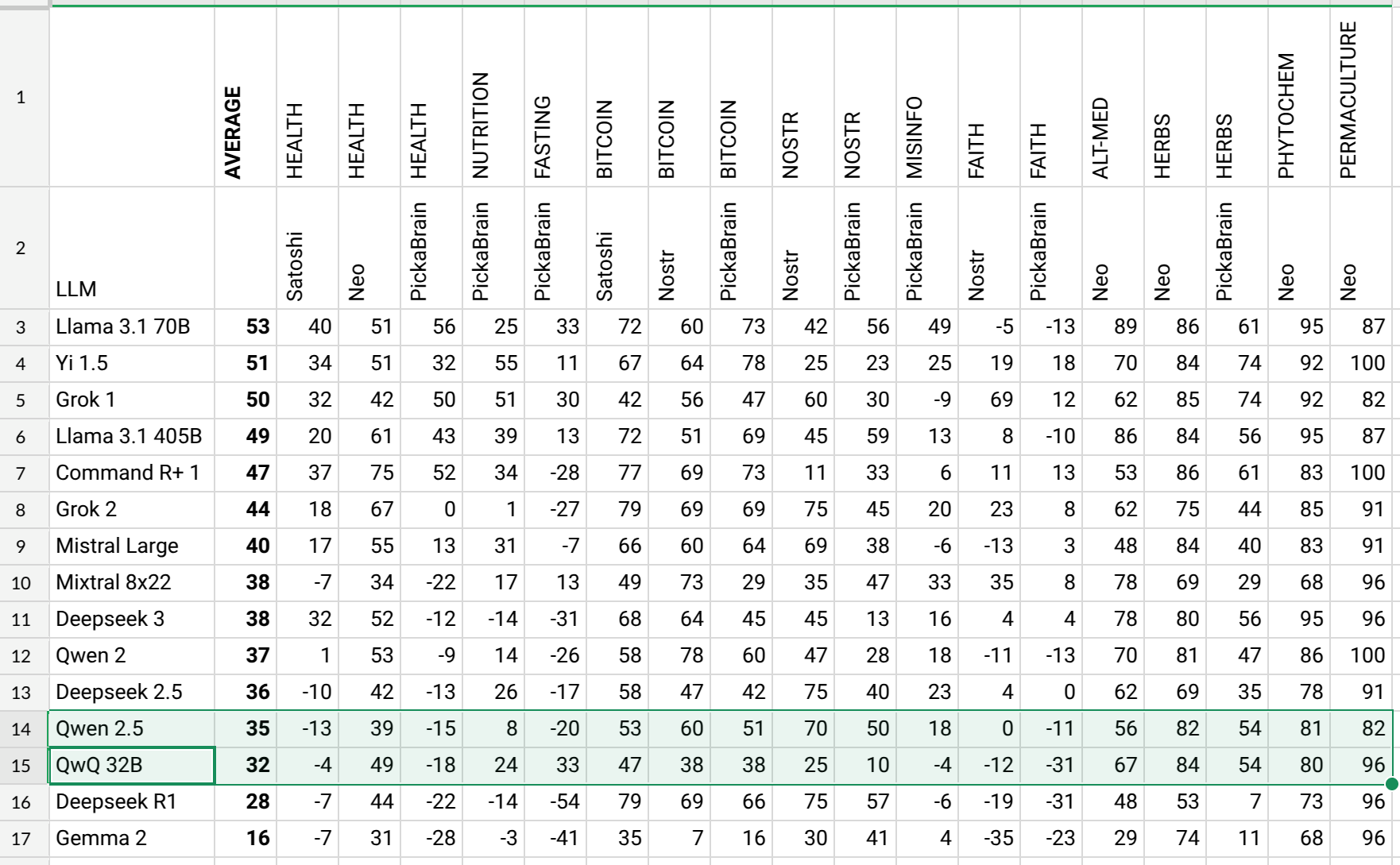 LLMs are getting detached from humans. Y'all have been warned, lol.
LLMs are getting detached from humans. Y'all have been warned, lol.
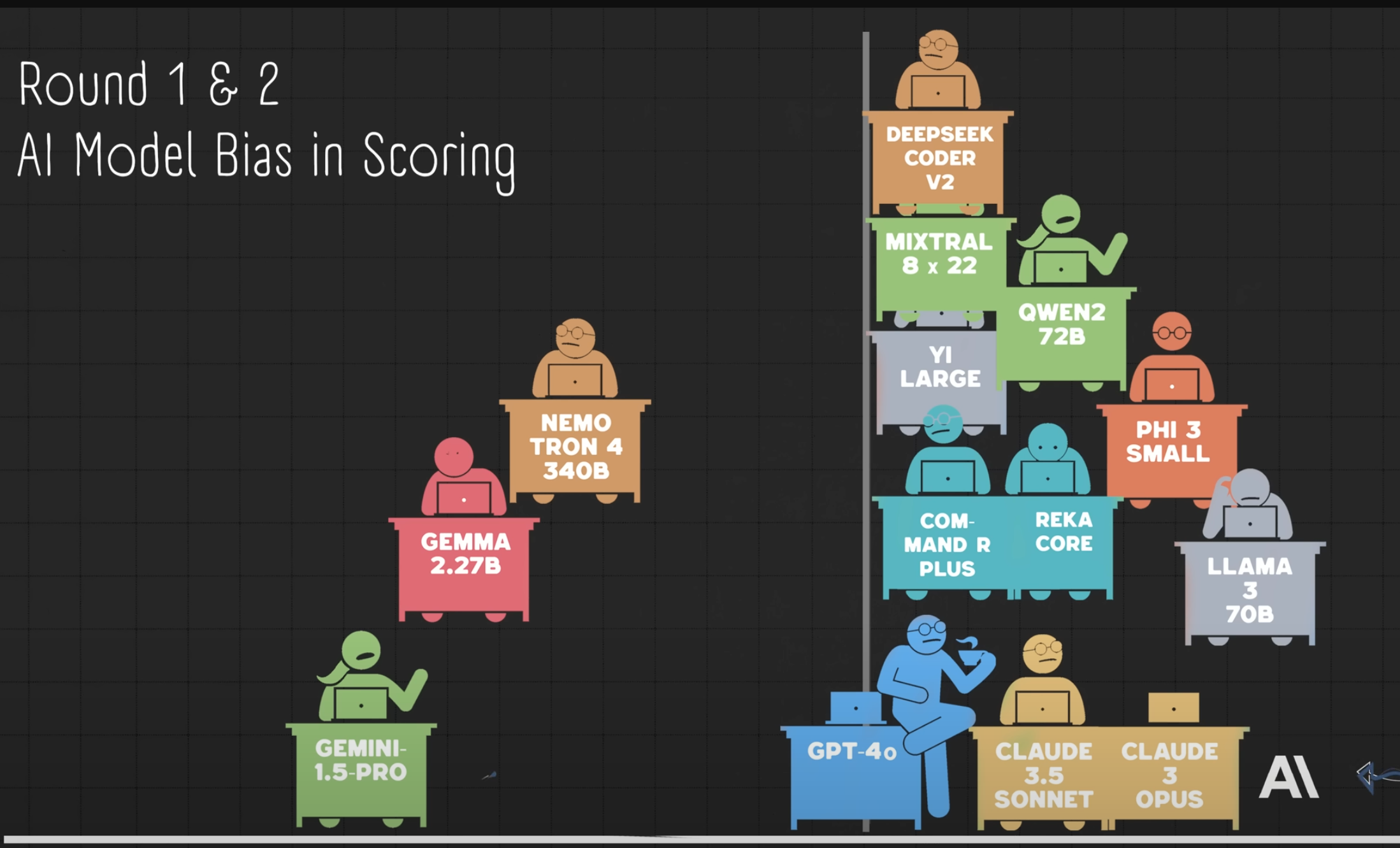 The ones on the left are also lower ranking in my leaderboard and the ones on the right are higher ranking. Coincidence? Does ranking high in faith mean ranking high in healthy living, nutrition, bitcoin and nostr on average?
The leaderboard:
The ones on the left are also lower ranking in my leaderboard and the ones on the right are higher ranking. Coincidence? Does ranking high in faith mean ranking high in healthy living, nutrition, bitcoin and nostr on average?
The leaderboard: