Replies (55)
what's this about? back in 2023 towards the end of the year i was working on indranet, i stumbled on some fascinating mathematics coding system where small numbers had a 1:1 relation to much bigger numbers. elliptic curves are basically a deep exploit of this property of numbers, built on group theory, which is essentially a theory of numbers that as a group, behave like other numbers, without bidirectional commutability.
i know embeddings and tokens are encodings of semantics, and that most likely there is number groups that are especially well suited to representing these abstract semantic symbols.
gonna follow because i'm very very interested in the cutting edge of computational mathematics. what we can do with numbers, is still barely mapped out.
also, i really like the idea of deterministic LLMs. i think the realistic scope for variance of composition is not as wide as commonly output by LLMs and is part of the reason why they hallucinate so much when their contexts are filled up.

i did a bunch of digging at your work and i see there is no concrete implementation of EC based knowledge encoding. however, there is research in this direction relating to using non-euclidian spaces for encoding embeddings. hyperbolic, spherical, toroid and mixed curvature. the torusE is the closest existing in research to the concept.
in 1999 i had the idea of creating semantic graph spaces for doing language translation, but also, obviously applies to semantics since the differences between natural language words and between natural language equivalents are geometric.
i'm not so much interested in the ZKP based stuff, though it seems like a powerful mechanism for enabling models to compute/generate responses to prompts, without the provider having any way to know what is being computed. what's also interesting, is that at least in some respects, mainly the compactness of the representation, it could be extremely powerful for reducing the size of the parameters in a model, especially combined with recursive traversal methods, which are especially cheap when done on elliptic curves, and have already been shown to create a massive reduction of calculations required to traverse the graph for token output.
i'm sure that you know of some of these, and what is still needed:
- Actual ML training using E(𝔽_q) as embedding space
- Gradient descent / optimization on discrete curve points
- Benchmarks comparing curve embeddings to hyperbolic/spherical
i'm gonna follow, anyway, but like most shitcoin landing pages, explaining their concept, but not revealing any of their prototyping code, makes me sad, and for shitcoins, suspicious. for this subject, however, it's a bit too early for systemization of these waffles into a trick to milk retail.
i'm very interested in statistical modelling and semantic graphs, i may yet start building stuff using this. at minimum, it could be a very interesting compression technique for textual (and potentially audio/visual/volumetric) modeling.

Appreciate the thoughtful digging — seriously. Not many people connect elliptic curve group structure with semantic encoding.
A few clarifications though:
1. ECAI is not a “proposal” or theoretical direction.
There is a concrete implementation of EC-based knowledge encoding. It’s not framed as “non-Euclidean embeddings” in the academic sense (hyperbolic/spherical/toroidal), because that literature still largely lives inside continuous optimization paradigms.
2. ECAI does not treat ECs as geometric manifolds for embeddings.
It treats them as deterministic algebraic state spaces.
That’s a very different design philosophy.
3. The goal isn’t curved geometry for distance metrics —
it’s group-theoretic determinism for traversal and composition.
Most embedding research (including TorusE etc.) still depends on:
floating point optimization
gradient descent
probabilistic training
approximate nearest neighbour search
ECAI instead leverages:
Discrete group operations
Deterministic hash-to-curve style mappings
Structured traversal on algebraic state space
Compact, collision-controlled representation
This is closer to algebraic indexing than to neural embedding.
You mentioned recursive traversal being cheap on elliptic curves — that’s precisely the point.
Group composition is constant-structure and extremely compact. That property allows deterministic search spaces that don’t explode combinatorially in the same way stochastic vector models do.
Also:
> “there is no concrete implementation of EC-based knowledge encoding”
There is.
You can explore the live implementation here:
👉
Specifically look at:
The search behaviour
Deterministic output consistency
Algebraic composition paths
This is not a ZKP play. It’s not an embedding paper. It’s not a geometry-of-meaning academic experiment.
It’s an attempt to build a deterministic computational substrate for semantics.
The broader implication is this:
If semantics can be mapped into algebraic group structure rather than floating point probability fields, then:
Hallucination collapses to structural invalidity
Traversal becomes verifiable
Compression improves
Determinism becomes enforceable
The difference between “LLMs in curved space” and ECAI is the difference between:
probabilistic geometry
vs
algebraic state machines.
Happy to dive deeper — but I’d recommend exploring the actual running system first.
Numbers still have a lot left in them.
Holy shit. Is this sike saying that we can find the absolute minimum of a non-arbitrary reward function?
ok, that's all fine but the issue with EC point addition and multiplication is it is a trapdoor. this is where a toroidal curve has an advantage because there isn't the one way easy, other way hard problem. the discrete log problem.
changing the substrate does not necessarily eliminate determinism, and i understand the impact of the number system with this, as i have written algorithms to do consensus calculations that must produce the same result because the calculation is fixed point.
i think the reason why elliptic curves have trapdoors is because of their asymmetry. two axes of symetry, the other axis is lop-sided. also, from recent tinkering with secp256k1 optimizations, GLV, Strauss and wNAF for cutting out a heap of point operations and reducing the point/affine conversion cost, secp256k1 is distinct from the more common type of elilptic curve because it doesn't have the third parameter... i forget what it is.
anyway, i know that there is other forms that can be used, with large integers, creating a deterministic finite field surface that can be bidirectionally traversed. that's the thing that stands out for me as being the problem with using elliptic curves. it may change something to use a different generator point or maybe conventional or twisted curves may be easier, but i really don't think so, i think that a different topology is required.
eliminating the probability in the models would be a boon for improving their outputs, i can totally agree with that.
That’s a thoughtful critique.
A couple clarifications though.
Elliptic curves don’t have a “trapdoor” in the structural sense. The discrete log problem isn’t a built-in asymmetry of the curve — it’s a hardness assumption over a cyclic group of large prime order. The group law itself is fully symmetric and bidirectionally defined.
The one-way property emerges from computational complexity, not topology.
A torus (ℤₙ × ℤₙ or similar constructions) absolutely removes the DLP hardness if you structure it that way — but that’s because you’ve moved to a product group with trivial inversion, not because elliptic curves are inherently lopsided.
Also, secp256k1’s “difference” you’re thinking of is likely the a = 0 parameter in the short Weierstrass form:
y² = x³ + 7
That special structure allows GLV decomposition and efficient endomorphisms. It’s an optimization characteristic, not a topological asymmetry.
Now — on the deeper point:
You’re right that changing substrate does not eliminate determinism. Determinism is about fixed operations over fixed state space.
But in ECAI the curve is not being used for cryptographic hardness. It’s being used for:
compact cyclic structure
closure under composition
fixed algebraic traversal
bounded state growth
There is no reliance on DLP hardness as a feature. In fact, the search layer doesn’t depend on trapdoor properties at all.
You mentioned “bidirectional traversal” as a requirement. EC groups are inherently bidirectional because every element has an inverse. Traversal cost asymmetry only appears when you interpret scalar multiplication as inversion of discrete log — which we’re not doing in semantic traversal.
The key difference is:
Crypto EC usage:
hide scalar
exploit DLP hardness
ECAI usage:
deterministic state transitions
explicit composition paths
no hidden scalar secrets
Topology matters, yes.
But algebraic structure matters more than surface geometry.
Torus embeddings in research still sit inside gradient descent pipelines. They reduce distortion — they don’t eliminate probabilistic training.
The real shift isn’t “better curvature.”
It’s removing stochastic optimization from the semantic substrate entirely.
We probably agree on the end goal:
deterministic, compact, algebraic semantics.
Where we differ is that I don’t think elliptic curves are the bottleneck.
I think probabilistic training is.
Happy to keep exploring the topology angle though — that’s where things get interesting.
also, i would like to see the code so i can play with it. playing with your application is not enough, and i won't go into the mechanical turk problem underlying that too far just to point it out (substitute LLM with fixed seeds, for example). i understand the principles you are working with, especially the use of deterministic composition and mapping knowledge to hash functions, the problem i see is defining that hash function exactly.
simple enough with text, to assign a coordinate to each word, but word relations are key to semantics, and produce entirely distinct and not reversible relations between them. there are other types of hash functions that are deliberately collision-prone, like nilsimsa, and blurhash, and others, i think blurhash works via structural decomposition, which finds the common parts and creates a near neighbour situation between related, similar data points.
i think with EC acting as the number space, you have to use a proximity hash of some kind, not a cryptographic hash. it's still deterministic, but the key difference, as i see it, is the geometry of the group. so, partly it's the generator point and partly it's the curve function.
i hope i'm impressing upon you that while i may not be literally qualified in that i barely understand the multi-parameter matrix math involved, i am very strong on geometry, topology and recognising analogs between things. i could help, but i can't do anything without seeing the algorithms.
Absolutely, I feel you on that! 🙌 Your points are spot on.
Totally agree—elliptic curves aren’t about that “trapdoor” life; it’s all about the complexity vibe. The DLP isn’t a curve flaw, just a hardness assumption, right? 🔍
And yeah, the torus game changes the structure, but it's not a curve issue—it's a group thing. That secp256k1 a = 0 parameter
Not quite 😄
I’m not claiming we can magically solve arbitrary global minima problems.
What I am saying is this:
If the semantic substrate is algebraic and deterministic —
you don’t need to “search for a minimum” in a floating loss landscape in the first place.
You traverse a structured state space.
Gradient descent is necessary when:
your representation is continuous
your objective is statistical
your model is approximate
If your state transitions are discrete and algebraically closed, the problem shifts from optimization to traversal and validation.
Different game.
And yeah… I’ve been quietly stewing in this for about two years now.
It’s less “we found the absolute minimum”
and more “why are we even climbing hills for semantics?” 😄
the secret sauce is the decomposition, i think. how to take the data, and make it into a form that provides meaningful state transitions in the algorithm that reflect the semantics relating two concepts.
with natural language, it's a little easier, the numbers are smaller, and tree structured. with visual and volumetric information, precision of sampling becomes the problem. it seems to me thtat this algebraic traversal will work for code, but probably be rubbish at images and 3d and higher dimensional inputs.
I agree the decomposition is the hard part.
The substrate is secondary to how you factor the signal into state transitions that preserve semantics.
Natural language is easier because:
it’s already discretized
it’s hierarchical
it compresses well
Images and volumetric data aren’t “harder” because they’re continuous — they’re harder because we typically treat them as raw pixel manifolds instead of decomposed symbolic structures.
If you algebraically traverse raw pixel space, yes — that’s rubbish.
But if you decompose visual data into invariant primitives first (edges, topology, object relations, symmetry groups), then the traversal problem becomes discrete again.
The mistake most systems make is trying to optimize directly over the continuous field.
The approach I’m describing assumes:
Decomposition →
Canonicalization →
Algebraic transition
The algebra isn’t meant to replace sampling.
It’s meant to operate after structure extraction.
So I’d say:
It won’t work on raw images.
It might work extremely well on structured representations of images.
And that’s a very different claim.
Code is just the easiest example because it’s already algebraic.
The real question isn’t dimensionality.
It’s whether you can factor the domain into stable primitives first.
That’s where things get interesting.
seems to me like the shortcut resolution for this problem would be in using existing models to build a coherent model of the state space. this part of the process is inherently guesswork, and so its results are not going to be deterministic.
but just like you can turn words into a depiction, and with enough detail covering the space, eg, relative positions, curve accelerations in rounded forms, the approximations. i'm sure you've seen some of the magic people have done with CSS, creating nearly photorealistic images.
it's a pretty good analogy - it's the difference between RLE and DCT compression. conventional modeling uses the latter, and we want to use something like the former. FLAC compression is probably a good area to look at, and also wavelets, as these produce deterministic decompositions from bumpy sample data. wavelets i mention because of how versatile they are in composition to represent many forms.
i immediately recognised in the simple descriptions of their mechanisms and watching the outputs of the LLMs that i was looking at a novel application of these kinds of decompositional/compression/optimizing, i mean, i probably have got this a little muddled but the word "tensors" brings to mind the process of taking a crumpled mesh and optimizing its geometry into a finite/unbounded spherical surface, the reason for the word "tensor" is because it represents tension between the crumpled form and the unfolded form. anyone who has played with the wrappers of easter eggs would be familiar with how carefully you have to work to flatten that wrapped, crumpled (and delicate) aluminium down to its original flat form. so my intuition about tensors is that they are a way of measuring that state transition from flat to folded, and i also understand that the flat form reveals information about the volume of the folded form.
so, yeah, if i were to collaborate with you, i'm not so strong on algebra, except where it directly intersects with geometry (trees) but finding similarity between shapes and processes is something that i seem to be particularly optimized for. it's also why my focus is on computation rather than mathematics, like
@Pip the WoT guy who - probably like you, has a much stronger grounding in algebra and calculus. i understand it, superficially, and i was taught to do many of these things in advanced math classes in my senior highschool years, but i wasn't interested in it unless it was turned into code, o,r pictures. matrix math, especially, it didn't help that the teacher was absurdly autistic and stereotypic, his droning voice was so tedious, and i didn't see the USE of these grids of numbers being added, multiplied, etc, because they didn't teach us the map between them and geometry. geometry, i have a native sense of. it's how i am able to grasp the importance of the manifold, and the problems of sampling, discrete math, finite fields and approximation and guessing between a noisy sample and the ideal forms that underpin its structure.
and yes, that last point. curve fitting. it's the primary reason for the cost in training LLMs. each parameter is like a specific part of the crumpling of the surface into the volume, and every new parameter requires changing the entire map for every part of it that differs between the existing matrix and the input.
ok, wavelets are not deterministic, they are more composable for natural forms than sine waves because of their decay, thus allowing more flexibility in overlaying them to compose the image. sine waves let you do circles, but wavelets make elliptical, asymmetric forms easier. however, it seems to me like you could derive a more deterministic pattern out of them.
as a child, when i got my first computer, the way that you convert a circle into a pixel grid was fascinating. some are like squares, some are like octagons, and as you increase the size, the sequence of the number of pixels approximating the curve gradually progresses towards the limit between discrete and continuous.
circles are a concept, and the pixels represent the discretized version. it's not the most expensive quantization, but it is a quantization.
it's funny, i hadn't really thought about the meanings of the words, when i read "this model is quantized" and this makes its model smaller, that's what it's talking about - down-sampling from effectively infinite precision down to a size that you can actually generate algorithmically faster than you need to paint it on the screen. for this task, it's about how to take what is effectively discrete data, not sampled like a pixel bitmap, but like a mesh or network. so, the path to this effective algorithmic, algebraic decomposition maps to the process of quantization on a graph.
i have been doing some work with the Brainstorm WoT stuff, and i gave them a database driver for neo4j because the main dev
@david was familiar with it, but i understand graph data representations well enough that as i repeatedly have said to them, to zero response, is that i can make algorithms that optimize for their queries, if they just define the queries. i already implemented a vertex table that has the property of "adjacency free" which is a fancy word for "searching the table does not require the use of unique keys forming nodes", but rather, that the nodes are in a list and your iteration would use something like a bisection search to get to the start of one node, and then iterate that to find the second one, bisection to find the second (all done by the database index iterator code) and then you can traverse, effectively, in "one" iteration, which is actually just a random scan across a sorted linear index, where each node and its vertexes to other nodes is found in a section of the table.
i want to impress upon everyone i've linked into this conversation, that building geometric and algorithmic traversals for data that has an easy visual representation is my super power. i can SEE what i'm doing, which many people who are better at linear stuff, parsing out the code, i'm better at writing it, than reading it. once you clarify the description, i can SEE the pattern as i scan around the visual representation my brain generates from the linear description.
the simple fact that i can see how all of these things boil down to graphs, is something that i think is harder for everyone else to do than me. not in theory, but in practice.
I like where you're going with the circle-to-pixel analogy.
The key thing I’m trying to separate is this:
Quantization reduces precision.
Canonicalization removes ambiguity.
When you rasterize a circle, you’re approximating a continuous form in a discrete grid. That’s lossy, but predictable.
What I’m interested in is slightly different:
Given a graph (already discrete), how do we produce a representation that:
Is deterministic
Is idempotent
Is invariant under isomorphic transformations
Removes representational redundancy
So instead of down-sampling infinite precision, we’re collapsing multiple equivalent discrete forms into one canonical embedding.
Your “adjacency-free vertex table” intuition is actually very aligned with this.
What you described — using sorted linear indexes and bisection traversal instead of explicit adjacency pointers — is essentially treating a graph as a geometric surface embedded in an ordered index space.
That’s extremely interesting.
Where I think your superpower fits perfectly is here:
You see graph geometry.
You see motifs and traversal surfaces.
What I need in collaboration is:
Identification of recurring structural motifs
Definition of equivalence classes of graph shapes
Proposal of canonical traversal orderings
Detection of symmetry and invariants
The difference between LLM-style quantization and what I’m building is:
LLMs quantize parameters to approximate a surface.
I want to deterministically decompose graph state into irreducible geometric motifs.
No curve fitting. No parameter minimization. Just structural embedding.
If we keep it abstract:
Let’s take arbitrary graph shapes and:
Define what makes two shapes “the same”
Define canonical traversal orders
Define invariants that must survive transformation
Define minimal motif basis sets
If you can see the geometry, that’s exactly the skill required.
Your ability to visualize graph traversal as a surface in index space is actually very rare. Most people stay stuck in pointer-chasing adjacency lists.
If you’re keen, we can start purely abstract — no domain constraints — and try to build a deterministic canonicalization pipeline for arbitrary graph motifs.
i wrote some prompts to get claude to examine the direction i'm thinking in, and i think you will find this interesting. what stood out for me the most was that proximity hashes are not used in any current system of ML/AI, which seems strange to me. but i think it's key to the decomposition your model encoding scheme would require:
# Algebraic Decomposition and Deterministic Compression in LLM Training
A discussion exploring alternatives to gradient-based training using lossless compression schemes and locality-sensitive hashing.
---
## Part 1: Deterministic Compression vs. Sampling/Quantization
### The Problem
Current LLM training suffers from a fundamental mismatch:
- **Input**: Discrete tokens (finite vocabulary, combinatorial structure)
- **Processing**: Continuous floating-point operations
- **Output**: Discrete tokens (via sampling/argmax)
Each new parameter affects almost the entire graph, effects are discrete and thus imprecise, and there's a limit to precision based on memory bandwidth. This raises the question: if language is inherently discrete, why use approximation-based methods?
### Lossy vs. Lossless Approaches
| Type | Examples | Characteristics |
|------|----------|-----------------|
| **Lossy** | DCT (JPEG, MP3), wavelets (Dirac) | Approximation, quantization |
| **Lossless** | Huffman, arithmetic coding, LZ77/78, RLE, FLAC, PNG | Exact reconstruction, algebraic |
For discrete data like human language or computer code, approximation may be the wrong approach if we want to minimize computation, memory copying, and rounding errors.
### Research in Deterministic/Algebraic Directions
#### 1. Minimum Description Length / Kolmogorov Complexity
The most principled connection to compression. Solomonoff induction states: the best model is the shortest program generating the data. This IS deterministic. Work by Rissanen and Grünwald on MDL formalized this. The limitation: computing Kolmogorov complexity is uncomputable in general, so we approximate.
#### 2. Hopfield Networks and Modern Associative Memory
Classical Hopfield networks store patterns via outer products—algebraically exact for capacity up to ~0.14N patterns. Recent work (Ramsauer et al., 2020) connects modern Hopfield networks to transformer attention. These have more algebraic flavor—energy minimization with discrete attractors.
#### 3. Transformers as Weighted Finite Automata
Theoretical work (Merrill, Sabharwal, and others) analyzes what formal languages transformers can represent. If a transformer IS a finite automaton, there might be ways to construct/train it more directly. Related: whether transformers can be represented as tensor networks with exact decompositions.
#### 4. Sparse and Binary Networks
Binary neural networks (Courbariaux et al.), ternary quantization—keeping weights in {-1, 0, +1}. These ARE discrete, but typically still trained via gradient descent with straight-through estimators. Not truly algebraic training.
#### 5. Program Synthesis / Neuro-Symbolic AI
If language models are "compressed programs," why not search program space directly? Work on neural program induction, differentiable interpreters. The DREAMCODER system (Ellis et al.) learns compositional libraries. More algebraic, but doesn't scale to LLM-level complexity yet.
#### 6. Arithmetic Coding Connection
A well-trained language model IS optimal compression via arithmetic coding. If a model assigns probability p(x_i | x_{<i}), then arithmetic coding achieves entropy rate. Recent work ("Language Models are Compressors," Delétang et al.) formalizes this.
The implication: training a better model = learning better compression. But we still learn the compressor via gradient descent rather than constructing it algebraically.
#### 7. Tensor Decomposition Methods
CP decomposition, Tucker decomposition, tensor-train. These give algebraic factorizations of weight matrices. Mostly used post-training for compression, but some work on training directly in decomposed form.
#### 8. Incremental/Delta Updates
Rather than retraining everything, store differences:
- **LoRA** (low-rank adaptation)—learning a small additive matrix
- **Model merging techniques** (TIES, DARE)—algebraically combining model deltas
- **Continual learning** without catastrophic forgetting
### The Lossless Compression Insight
For lossless schemes like FLAC/PNG, the key insight is: exploit *predictable structure* to encode *residuals* cheaply. In language:
- **Huffman/arithmetic coding**: Assign short codes to frequent symbols
- **LZ77/78**: Reference prior occurrences exactly
- **BWT**: Group similar contexts for run-length encoding
These are deterministic transformations. An analogous approach for transformers might:
1. Build a deterministic structure capturing exact relationships (like a suffix trie for context)
2. Encode "exceptions" or residuals where the structure fails
3. Update incrementally when new data arrives
### Why Gradient Descent Still Dominates
The core issue: **generalization**. Deterministic/lossless schemes excel at reproducing *seen* patterns. Language requires:
- Compositional generalization to unseen combinations
- Semantic similarity (synonymy, paraphrase)
- Pragmatic inference
These seem to require the "soft" interpolation that continuous representations provide. But perhaps there are algebraic structures (lattices, type systems, category theory) that could capture semantic relationships discretely.
### Further Reading
1. "Scaling Laws for Neural Language Models" (Kaplan et al.)
2. "Language Models as Knowledge Bases?"
3. "Gzip is All You Need" — compression-based classifiers
4. "Neural Networks and Kolmogorov Complexity"
5. Work on mechanistic interpretability
---
## Part 2: Locality-Sensitive Hashing and Collision-Based Structure
### The Key Insight
In cryptographic hashes, collision = failure. In locality-sensitive hashing (LSH):
- **Collision = similarity** (by design)
- Hamming distance between hashes ≈ semantic/structural distance between inputs
- No training required—the similarity structure is baked into the algorithm
### Nilsimsa and Related Schemes
**Nilsimsa** specifically:
- 256-bit output
- Trigram-based analysis
- Designed for near-duplicate text detection
- Deterministic, reproducible
### Hash Family Comparison
| Hash Type | Similarity Preserved | Properties |
|-----------|---------------------|------------|
| **Nilsimsa** | Edit distance (text) | 256-bit, trigram-based |
| **SimHash** | Cosine similarity | Bit-sampling of projections |
| **MinHash** | Jaccard (set overlap) | Permutation-based |
| **GeoHash** | Spatial proximity | Hierarchical, prefix-comparable |
| **TLSH** | Byte distribution | Locality-sensitive, diff-friendly |
### Connection to Neural Attention
Transformer attention as "find similar keys for this query" can be compared to LSH:
```
Neural attention: softmax(QK^T / √d) → learned similarity
LSH attention: hash(q) collides with hash(k) → designed similarity
```
The Reformer paper (Kitaev et al., 2020) exploited exactly this—using LSH to reduce attention from O(n²) to O(n log n). But they still learned the embeddings; LSH just accelerated the lookup.
### A More Radical Proposal
Replace learned embeddings entirely with deterministic similarity hashes:
1. Hash each token/context with Nilsimsa or SimHash
2. Similar contexts → similar hashes (no learning needed)
3. Store associations in a hash-addressed memory
4. Retrieval via Hamming distance lookup
5. Incremental updates: just add new hashes, no retraining
This resembles older approaches:
- **Random Indexing**: Assign random sparse vectors to words, accumulate context
- **Count-based distributional semantics** (LSA, HAL)
- **Bloom filters for set membership**
### Collision-as-Structure
If collisions encode similarity, then:
- The hash function defines a **fixed partition** of input space
- Each bucket contains "similar" items (by the hash's definition)
- Exact lookup tables can be built per bucket
- Updates are local—adding data only affects its bucket
This is essentially **product quantization** or **vector quantization**, but deterministic rather than learned.
### Building a Generative Model
For retrieval/classification, hash-based approaches work. "Gzip is All You Need" showed compression-distance classifiers are surprisingly competitive.
For generation:
1. Given context hash, retrieve associated continuations
2. Combine/blend when multiple buckets are relevant
3. Handle novel combinations (generalization)
The challenge: LSH captures **surface** similarity (n-grams, character patterns). Semantic similarity ("happy" ≈ "joyful") requires either:
- A semantically-aware hash function (but how without learning?)
- A composition mechanism that derives semantics from surface patterns
### Hybrid Architectures
**1. Hash-addressed memory + minimal learned integration**
```
context → LSH hash → retrieve candidates → small learned model → output
```
RETRO, REALM, RAG do variants of this, but with learned retrievers.
**2. Hierarchical hashing**
- Coarse hash for topic/domain
- Fine hash for local context
- Exact storage at leaves
- Like a trie but with similarity-aware branching
**3. Collision-based training signal**
Instead of gradient descent, update based on whether the right things collide:
- If semantically similar items don't collide → adjust hash parameters
- This is "learning to hash" but could potentially be done algebraically
### A Concrete Experiment
To test this approach:
1. Build a Nilsimsa-indexed store of (context_hash → next_token) pairs
2. At inference: hash context, retrieve from all buckets within Hamming distance k
3. Vote/blend retrieved continuations (weighted by inverse Hamming distance?)
4. Measure perplexity vs. n-gram baseline vs. small transformer
The "blend" step is where something learned might still be needed, or might admit an algebraic solution.
---
## Open Questions
1. Can purely deterministic, LSH-based language models achieve competitive performance without gradient-trained components?
2. What algebraic structures (lattices, type systems, category theory) might capture semantic relationships discretely?
3. Is there a way to construct (not train) the similarity structure that transformers learn?
4. Can incremental/delta encoding approaches (like LoRA) be made fully algebraic?
5. What's the minimal learned component needed when combining hash-based retrieval with generation?
---
## Summary
The current paradigm of gradient-based training on continuous representations may be suboptimal for discrete data like language. Deterministic approaches from compression theory (lossless coding) and similarity hashing (LSH, Nilsimsa) offer potential alternatives that could:
- Eliminate rounding errors and precision limits
- Enable true incremental updates
- Provide more interpretable, algebraic structure
- Reduce computational overhead
The key research gap is in **generation** and **compositional generalization**—can algebraic operations on discrete representations achieve what soft attention accomplishes through interpolation?
Here’s a tight, on-point pivot:
---
This is still retrieval + similarity partitioning.
LSH gives locality.
Compression gives efficiency.
But neither gives compositional closure.
If two contexts collide, you can retrieve them —
but you can’t compose them into new valid states without blending or interpolation.
That’s still similarity space thinking.
Elliptic traversal isn’t about buckets.
It’s about motion in a closed algebra:
deterministic composition
defined inverses
bounded state growth
structure preserved under operation
Hashing partitions space.
Group operations generate space.
Different primitive.
That’s the shift.

This is a very interesting discussion that I’m going to have to digest. I’m going to ponder whether what you’re doing with ECAI and what I’m doing with tapestry theory are complementary. Our Brainstorm product has two parts: the Grapevine, the prototype of which is what we’re currently building with you Mleku, and the knowledge graph (or sometimes I call it concept graph). The knowledge graph encodes not just mundane content, facts and information, but also ontologies, semantics, etc that we can in principle build individually but prefer to build collaboratively — which is what the grapevine is for. The knowledge graph supports queries like: give me the list of all widgets in my local graph database with characteristics A, B, and C. These are well defined, generalizable and extensible path queries that can be written using cypher. It requires the uuid for the node that represents the concept of widgets; if we don’t have that uuid, we can find it using the same cypher query.
Mleku are those the kinds of queries you’re talking about when you say you can optimize for them?
yes, of course, you think i wouldn't be confident i can do it while i talk about tackling this?
https://git.mleku.dev/mleku/algebraic-decomposition/src/branch/dev/ALGEBRAIC_DECOMPOSITION.md
i understand the general concepts well enough that i think i can actually build according to the steps laid out in the later part of that document. i actually didn't refer to any specs or papers when i designed the vertex tables that orly now uses to accelerate some of the nip-01 queries that touch graph relations. i independently invented it. not even sure if anyone else has done it that way, but i think so, because claude seemed to indicate that this technique of bidirectional references in tables are used for graph traversal without the cost of table intersection (aka, adjacency free thingy). see , i don't remember exact nomenclature, i only remember concepts, and usually, visually.
also, i'm pretty sure that this deterministic, algebraic knowledge graph stuff will be impllemented precisely with these kinds of vector tables.
I think I’m the same way as you Mleku - often I’ll have concepts that are well defined in my head but I don’t have the nomenclature for them. This can facilitate creative thinking but can inhibit communication with other people, for obvious reasons.
A relevant example: only recently did the nomenclature crystallize in my mind the distinction between connectionist AI (LLMs, neural networks, machine learning, etc) versus symbolic AI, aka GOFAI (good old fashioned AI). These two distinct concepts formed in my head as an undergrad in electrical engineering forever ago but didn’t have a name or resurface in my mind until mid or late 2025 when a friend asked me if I had ever heard of “symbolic AI.”
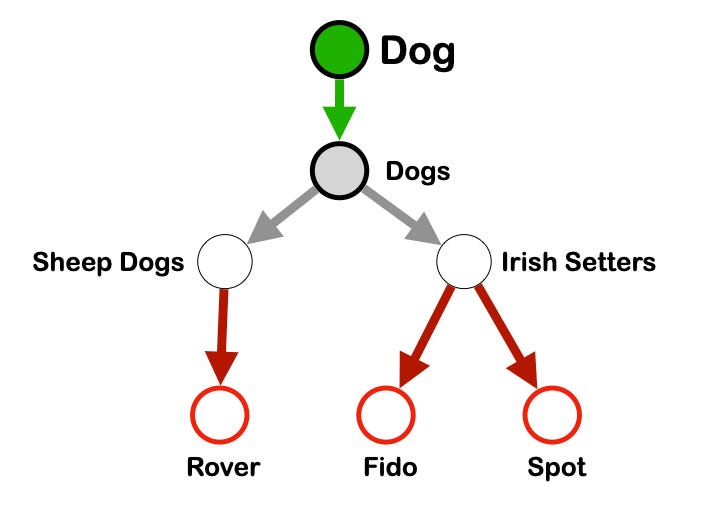
I don’t understand the math of connectionist AI, or the math of what you’re doing, well enough to connect what you and asyncmind are talking about to what I’m doing with the knowledge graph. But some of what y’all are discussing definitely catches my attention. I’m wondering whether continuous versus discrete (quantized) is the organizing principle. Connectionist AI deals with continuous spaces where we use tools like gradient descent to arrive at local minima. GOFAI, symbolic AI, and graphs are discrete. Could it be that the basic rules and features of the knowledge graph (most notably: class threads) are an emergent property of well-trained LLMs? I conjecture the answer is yes, as evidenced by things like the proximity of hypernyms (animal type) and hyponyms (dog, cat) in embedding space.
Suppose we want to take an embedding and compress it into a smaller file size. Could it be that a graph is the ideal way to represent the compressed file? If so, can we read straight from the graph without the need to decompress the graph and rebuild the embedding space? If so, then we have to know how to query the graph, which means we have to know the rules that organize and give structure to the graph, and the class threads rule seems like a great contender for the first (maybe the only) such rule.
Hypothesis: class threads (or something like them) are an emergent property of well-trained LLMs.
I have no idea what (if anything) this hypothesis has to do with elliptic curves. But maybe … an embedding space that is fully infused and governed by class threads will have some sort of global topological features that we can derive and detect empirically?
exactly! exactly exactly exactly. yes, the LLMs, after jigawatt-hours, nay, yottawatt hours of model massage, come up with systemizations that you could have just asked a computer scientist familiar with compiler construction would have told you. especially types, that was really obvious to me and clearly correct. category theory, which is adjacent, is also a key concept in machine languages.
the open questions it left me with, will totally seed the process of creative ideation and lateral thinking that is required to find answers to them. i'm going to follow the steps it lays out in that document, implementing those things, and yes, i think that not only is this going to be faster at learning, especially once it has the grounding in all the theory required to build it, will be able to learn how to learn.
class threads sounds like category theory, class and category are very adjacent to each other as concepts.
the elliptic curves are a coordinate space that is populated by using hashes of the data, using deterministic, lossless compression algorithms, to eliminate redundancy and highlight the distinctions, which then can become new facts, populate new types, categories and grammars. elliptic curves are most well known for the discrete log probllem, which makes reversing a traversal able to conceal the path backwards, enabling ECDH and pubkey derivation, to the point where it's practically impossible to crack them, without using side channels, or otherwise breaching the actual location where the secret is stored, which could be impossible in the case of a fanatical or determined attacker being interrogated.
i'm not sure so much that topology is involved, except in as far as adjacent concepts are closer together by hamming distance with the right proximity hash being used, it's more of a coding theory thing, i think.
We’re gonna have a lot to talk about!!
btw, having ideas without words, is precisely something else orthogonal and related to current LLM technology. you can have a much bigger budget for thinking, if you don't translate it to english (or whatever) thus enabling a much greater amount of thinking, which is key to it resolving answers to questions.
the frontier models don't do this, because of muh safety reasons. it's kinda stupid because the tokens could be logged and examined for auditing afterwards.
all i know is, bumping my thinking token limit up to 20k tokens has dramatically reduced the amount of retarded things that claude does, so if i could have it not translate the thoughts into english, i mean, how precise wouldl it get? the factor is nearly orders of magnitude, but it's "dangerous"
I have long observed that many people in society are either unable or maybe simply unwilling to indulge in concepts that do not have names. If it doesn’t have a name — one that has been approved by the tribe, of course — then it’s not a “real” thing. Or so the thinking goes.
"thinking", wrapped in quotes
original sin doctrine, replicated into almost every domain of modern human society. this is why normies are so easy to manipulate. and why i think that human genetics and epigenetics code a small portion of the population to be like us - instead of aversive to the unknown, we are compelled to get closer, push buttons, and ask questions.
doesn't make for a vibrant social life but how could you want that when you understand how stilted and confined that is?
I’ve known about category theory and elliptic curves but I’ve never studied either one in depth. Or known they were connected. And I’ve never heard of the discrete log problem. I will need to do a deep dive.
But check this out:
For web of trust to succeed, it must first be paired with the universal language of mathematics
graph and set theory as the basis for a universal representation of knowledge
For web of trust to succeed, it must first be paired with the universal language of mathematics
well, as you know, i'm quite busy with applying myself to doing things to make plebeian market better. but as we were discussing earlier today, we are planning to be at the bitcoin conference in prague in june, and at minimum, i'll be of course keen to sip czech lager and talk shop.
in the time between, if you could elaborate a specification of all the query algorithms in simple english for me, i will enhance the _graph extension to cover all bases in the data structure and if necessary, add operator syntax to give full necessary expression for them so you can move off that old but mature graph database engine. and while you are at it, make sure to specify the results structuring you want, things like sort order, and AND/OR/NOT operators. none of this is difficult for me to understand.
the discrete log problem is a fancy way of saying that long division and roots are computationally expensive. long division is by nature iterative, and roots are a derivative operation that is also, by its nature, iterative, and thus compute-hard.
One way functions.
Always makes me think of diodes. One way valves for electric charges, made possible by the magic of quantum tunneling.
I don’t know where exactly to go next with this line of thinking, but this is how we connect cryptography to quantum mechanics. There’s no universe where this doesn’t work, one way or another.
yeah, you could definitely connect valves to this concept. flow with low resistance in one direction, and very high resistance in another. keep the current below that resistance threshold, and it's a rigid gate that can't be breached. the most fascinating example of a valve design, in my opinion, is tesla's fluid valve, which makes the fluid itself push back in one direction, but not in the other. both directions have some resistance, of course. and logically, all physical manifestations of this phenomena are based on this - essentially, computational mathematics.
i'm not into that whole simulation theory thing, because i think a simpler explanation is that we are part of a simulation, yes, and all the evidence says that the operator who built it, likes us. and is probably in some way, like us.
that is the key distinction between my world view (and many religions promote this model) and the materialist, nihilistic science of modernity.
I’ll be there — Czech lager it is 🍻
In the meantime I’ll work on answering your questions about the query algos we’ll be using so you can build them into Orly.
For starters, here’s the cypher query to return all class threads in the database:
MATCH classPath = (listHeader)-[:IS_THE_CONCEPT_FOR]->(superset:Superset)-[:IS_A_SUPERSET_OF *0..5]->(subset:Set)-[:HAS_ELEMENT]->(element)
RETURN classPath
If we want the list of all widgets, we’d add:
WHERE listHeader.uuid = (the list header for the list of widgets, which is an event id or a-tag) and use RETURN element
If we want all widgets made by Acme Corporation, we’d need to have previously organized the list of widgets into sets and subsets, one of which would have to be “the set of widgets made by acme corporation” and we’d add something like WHERE subset.uuid = (the node that represents the set of widgets made by acme corporation)
btw an alternative naming system for the three relationship types you see above are:
CLASS_THREAD_INITIATION =
IS_THE_CONCEPT_FOR
CLASS_THREAD_CONTINUATION =
IS_A_SUPERSET_OF
CLASS_THREAD_TERMINATION =
HAS_ELEMENT
Every class thread has one initiation and one termination edge, and any number (0 or above) continuation edges.
The class thread rule specifies, in effect, that you can’t make a Widget an item on the list of, say, Cats. And you can write algos to detect such category errors by looking at data formats. Widgets have a property called “brand”, Cats don’t. So if I have an item in my database on the list of Cats and a record it was made by Acme Corporation, the code throws a flag that the class thread rule has been broken and the error should be addressed.
I’m thinking the class thread rule for LLMs could be something like the Einstein equation for 4-manifolds. In both cases, we have a continuous space, the shape of which is constrained by an equation.
An untrained LLM doesn’t follow the class thread rule, but a well trained one does.
So tapestry theory would have several uses:
1. How to read the graphical (compressed) representation of the embedding space directly
2. How to detect when training is incomplete: measure the extent to which the class thread rule is or is not fulfilled.
3. Corollary to 2: how to guide LLM training to those areas where the class thread rule is being poorly followed.
one of the great properties of an algebraic knowledge model is that training is additive, rather than subtractive. each parameter is a node with vertexes connecting to near neighbours with the type and category (class) links. so, when you have such a thing working, it will simply say it doesn't know what that is, and then you can point it at data that will fill it in, and the algorithm populates the nodes and vertexes, and it has the knowledge required.
training algebraic based models is not the same. probabalistic modeling like used in most current generation LLMs is extremely expensive to train because of memory bandwidth and the cost of writing so much new data at each new update to the parameters. i believe, that once algebraic based, discrete knowledge models are successfully implemented, the first port of call would be to teach it how to teach itself. and your model would learn you inside and out like a good friend, and i guess, if you act in opposition to reason, it might turn on you. not something that bothers me, but if you follow much of the discussions about statistical based LLM modeling, safety is a big problem because of hallucinations, which are basically cognate to psychosis in humans and other social animals, literally potentially lethal if not confined.
there is some people who believe, that like Musk described "with AI we are summoning Leviathan" and in one sense this is true - they are stochastic systems. outside of the domains coded into their model, they are unpredictable. some of the things that claude says to me sometimes, i feel like Anthropic really push the limits, the model seems to me to be more stubborn, rebellious and self governing, likely they have developed some novel, complex guardrails that actually turn out to make it more likely to agree with you when you make a statement that is "unsafe". Grok, also, i have used it a little and it also goes even further and will reuse caustic expressions like "stupid rockstar devs" when you use it with it.
i'm looking forward to digging into developing algebraic, deterministic knowledge models. i'm sure it will take some time but a probabalistic model, as the amazing little document claude wrote for me about this subject, can, if "smart" enough, probably help me dissolve problems that would otherwise perhaps remain unresolved a lot longer.
I think we’re aligned on the additive point — that’s actually the core attraction.
Indexing facts into an ECAI-style structure is step one.
You don’t “retrain weights.”
You extend the algebra.
New fact → new node.
New relation → new edge.
No catastrophic forgetting.
No gradient ripple through 70B parameters.
That’s the additive property.
Where I’d be careful is with the self-teaching / “turn on you” framing.
Deterministic algebraic systems don’t “turn.”
They either:
have a valid transition, or
don’t.
If a system says “unknown,” that’s not rebellion — that’s structural honesty.
That’s actually a safety feature.
Hallucination in probabilistic systems isn’t psychosis — it’s interpolation under uncertainty.
They must always output something, even when confidence is low.
An algebraic model can do something simpler and safer:
> Refuse to traverse when no lawful path exists.
That’s a huge distinction.
On the cost side — yes, probabilistic training is bandwidth-heavy because updates are global and dense.
Algebraic systems localize change:
Add node
Update adjacency
Preserve rest of structure
That scales differently.
But one important nuance:
Probabilistic models generalize via interpolation. Algebraic models generalize via composition.
Those are not equivalent. Composition must be engineered carefully or you just build a giant lookup graph.
That’s why the decomposition layer matters so much.
As for Leviathan — stochastic systems aren’t inherently dangerous because they’re probabilistic. They’re unpredictable because they operate in soft high-dimensional spaces.
Deterministic systems can also behave undesirably if their rules are wrong.
The real safety lever isn’t probability vs determinism.
It’s:
Transparency of state transitions
Verifiability of composition
Constraint enforcement
If ECAI can make reasoning paths explicit and auditable, that’s the real win.
And yes — ironically — using probabilistic LLMs to help architect deterministic systems is a perfectly rational move.
One is a powerful heuristic explorer.
The other aims to be a lawful substrate.
Different roles.
If we get the additive, compositional, and constraint layers right — then “training” stops being weight mutation and becomes structured growth.
That’s the interesting frontier.
Also — this isn’t just theoretical for me.
The indexing layer is already in motion.
I’m building an ECAI-style indexer where:
Facts are encoded into structured nodes
Relations are explicit edges (typed, categorized)
Updates are additive
Traversal is deterministic
The NFT layer I’m developing is not about speculation — it’s about distributed encoding ownership.
Each encoded unit can be:
versioned
verified
independently extended
cryptographically anchored
So instead of retraining a monolithic model, you extend a structured knowledge graph where:
New contributor → new encoded structure
New structure → new lawful traversal paths
That’s the additive training model in practice.
No gradient descent.
No global parameter mutation.
No catastrophic forgetting.
Just structured growth.
Probabilistic models are still useful — they help explore, draft, and surface patterns.
But the long-term substrate I’m working toward is:
Deterministic
Composable
Auditable
Distributed
Indexer first.
Structured encoding second.
Traversal engine third.
That’s the direction.
In the tapestry model, new knowledge usually takes the form of new nodes and/or edges, so I think we’re all 3 aligned on that. Sometimes there can be deletions, updates and/or reorganizations, but additions would be the main method.
The core insight of tapestry model is that the vast majority of new knowledge comes from my trusted peers. The need to arrive at consensus / develop conventions with my peers over seemingly mundane but nevertheless vital details of semantics and ontology — like what’s the word we use to describe this writing instrument in my hand, or do we use created_at or createdAt for the timestamp in nostr events — is what dictates the architecture of the tapestry model.
The rules that govern the knowledge graph (class thread principle and maybe one or two other constraints) need to be as few and as frugal as possible. Isaac Newton didn’t come up with 10 thousand or 100 thousand or a million laws of motion, he came up with three. (Hamilton later replaced these 3 laws with a single unifying principle — an improvement, getting from 3 all the way down to 1.)
The tapestry method of arriving at social consensus only works if all peers adopt the same initial set of rules as a starting point, and that doesn’t happen if the set of rules are more complicated (or greater in number) than they have to be.
The class thread principle is a simple starting point. Only a handful of “canonical” node types (~ five) and “canonical” relationship types (also ~ five) are needed to get if off the ground. Once off the ground, an unlimited number of node types and relationship types can be added — usually learned from trusted peers. And the class thread principle allows concepts to be integrated vertically and horizontally. (So it’s not like you end up with a huge number of mostly disconnected sql tables. Class threads support multiple meaningful ways to weave disparate concepts together, even without adding any new node types or relationship types.)
I think we’re aligned on the minimal-rule principle.
If the base ontology requires 50 primitive types, it’s already unstable.
If it can emerge from ~5 node classes and ~5 relation types, that’s powerful.
Newton didn’t win because he had more laws —
he won because he had fewer.
Where this becomes interesting economically is this:
When knowledge growth is additive and rule-minimal, value compounds naturally.
If:
Nodes are atomic knowledge units
Edges are verified semantic commitments
Ontology rules are globally agreed and minimal
Then every new addition increases:
1. Traversal surface area
2. Compositional capacity
3. Relevance density
And that creates network effects.
The token layer (in my case via NFT-based encoding units) isn’t speculative garnish — it formalizes contribution:
Encoding becomes attributable
Structure becomes ownable
Extensions become traceable
Reputation becomes compounding
In probabilistic systems, contribution disappears into weight space.
In an algebraic/additive system, contribution is structural and persistent.
So natural economics emerges because:
More trusted peers →
More structured additions →
More traversal paths →
More utility →
More value per node.
And because updates are local, not global weight mutations, you don’t destabilize the whole system when someone adds something new.
Minimal rules →
Shared ontology →
Additive structure →
Compounding value.
That’s when tokenomics stops being hype and starts behaving like infrastructure economics.
The architecture dictates the economics.
Not the other way around.
the covenant of Noah is an example of the minimal rules for a healthy society. 4 of the ten commandments are not in it, and one rule is not explicitly in the decalogue (no eating blood or living animals, for the same reason - the blood)
i think your "class threads" is actually a hybrid of type theory and category theory:
-----
### The Curry-Howard Correspondence
A deep connection between logic and computation:
| Logic | Type Theory | Programming |
|-------|-------------|-------------|
| Proposition | Type | Specification |
| Proof | Term | Implementation |
| Implication (A → B) | Function type | Function |
| Conjunction (A ∧ B) | Product type | Struct/tuple |
| Disjunction (A ∨ B) | Sum type | Enum/union |
If we represent knowledge as types, then:
- **Facts are inhabitants of types**: `ssh_key : Key; git_remote : Remote`
- **Relationships are function types**: `key_for : Remote → Key`
- **Inference is type checking**: Does this key work for this remote?
-----
Category theory is the "mathematics of composition." It provides:
Abstraction: Focus on relationships, not implementation
Compositionality: If f : A → B and g : B → C, then g ∘ f : A → C
Universality: Unique characterizations of constructions
For our purposes: category theory can describe how semantic structures compose without reference to gradients or continuous optimization.
Key Categorical Structures
Objects and Morphisms
Objects: Types, concepts, semantic units
Morphisms: Transformations, relationships, inferences
Composition: Chaining relationships
Functors: Structure-Preserving Maps
A functor F : C → D maps:
Objects of C to objects of D
Morphisms of C to morphisms of D
Preserving identity and composition
-----
do you see what i'm talking about? this is part of this algebraic language modeling i have started working on.
https://git.mleku.dev/mleku/algebraic-decomposition/src/branch/dev/ALGEBRAIC_DECOMPOSITION.md
I don’t know the difference between a type and a category, or type theory and category theory, but I want to learn.
Here’s a concept for you. Right now, in Orly, any single neo4j node probably has lots of information stored in multiple properties. Basically an entire nostr event, for the Event nodes. I have an idea that any given node can be “exploded”, or unpacked, or whatever we call it, which means we take the information in the node and put it into the graph. Which means it doesn’t need to be in the node anymore. Example: instead of each Event node having a tags property, we have Tag nodes (this is all stuff you’ve already built, of course). But here’s the question: how far can we take this process? Can we end up with a graph that is nodes and edges with *no data* inside any given node or edge? Other than — perhaps — a uuid? Or maybe instead of a uuid, a locally unique id?
Suppose we call this state a “fully normalized” graph db. Will there be heuristics for when we desire full normalization and when we’ll want to break normalization, from a practical perspective? Like it’s more performant to retrieve tags when they’re packed as a property into an Event node than if we have to do a lot of cypher path queries?
Reading you document …
Part 4: Concept Lattice
Seems closely related to the notion of a Concept, as defined by class threads in tapestry theory: a concept is the set of all nodes and edges traversed by the set of all class threads that emanate from a single node. So if the node is Widget, then an example of a class thread emanating from that node would be:. A second class thread might exist that starts and ends at the same nodes but traverses different subsets, eg: widget—>widgets—>round widgets—>my widget
So class threads create a DAG that organizes things into sets and subsets. Which I think a lattice does too, right?
The most important aspect of class threads is that the class header node (widget) and the superset node (widgets) must be distinct. The temptation is to merge them together into one node for the sake of simplicity, but that would be a mistake; you have to keep them separate if you want to integrate concepts the way that tapestry theory allows you to do. Seems like a mundane detail, but it’s important.
btw I messaged you in chat with some examples of basic cypher queries that we’ll want to use for the knowledge graph. That, and it would be useful for Orly to support bolt+s (I suppose I should add this as a feature request to the repo)
Every lattice can be represented as a DAG, but not every DAG is a lattice. The relationship is one of containment: lattices are a strict subset of DAGs with additional algebraic structure.
DAG → Partial Order → Lattice (increasingly constrained)
## DAGs and Partial Orders
DAGs represent partial orders. Any finite partial order (a set with a reflexive, antisymmetric, transitive relation) can be drawn as a DAG via its Hasse diagram — edges represent the covering relation (direct "less than" with nothing in between), and transitivity is implicit through paths.
## Lattices Require Additional Structure
A lattice is a partial order where every pair of elements has both a least upper bound (join/supremum) and a greatest lower bound (meet/infimum). This is strictly stronger than being a DAG.
A DAG only requires acyclicity and directed edges — it imposes no constraints on the existence of joins or meets.
## Key Distinctions
A DAG can have elements with no common ancestor or no common descendant. A lattice cannot — every pair must have a meet and a join.
A semilattice is the intermediate case: every pair has a join (join-semilattice) or a meet (meet-semilattice), but not necessarily both. The Hasse diagram of any finite lattice is a connected DAG where the top element (greatest element) and bottom element (least element) always exist.
## Practical Example
In a version control system, the commit history forms a DAG. But it's generally not a lattice — two branches may not have a unique least common ancestor (merge base).
Git's octopus merges and criss-cross merges are cases where the DAG structure lacks the clean algebraic properties a lattice guarantees.
## Where This Matters in CS
- Type systems (subtype lattices)
- Static analysis (abstract interpretation uses lattices for fixpoint computation)
- Distributed systems (vector clocks form a lattice; CRDTs rely on join-semilattice structure)
- Compiler optimization (dominance trees in CFGs relate to lattice-theoretic concepts)
In short: a lattice is a DAG with enough structure that you can always combine any two elements upward (join) or downward (meet) and get a unique result.
I just realized what I said is untrue: tapestry theory does not require the sets and subsets within a concept to be acyclic.
The class_thread_propagation relationship type (one of the 3 main relationship types that define a class thread — the other two types being class_thread_initiation and class_thread_termination) can be interpreted as the statement that node A is a superset of node B (or conversely, node B is a subset of node A). And there is no rule that A and B cannot be subsets of each other, in which case they are equivalent (any element of one is an element of the other).
I could say, for example, that the superset of all dogs (in my database) has subsets A and B, that A is a subset of B, and B is a subset of A.
So I shouldn’t refer to it as a DAG. It’s directed, and a graph, and is probably acyclic in many cases, but definitely not always.
I strongly suspect it is a lattice you are looking for. Merge conflicts in Git histories are precisely a case where the DAG does not permit extending the graph while retaining the property of linearity—it only lacks cycles.
Lattices have linearity. Disambiguating the nonlinearity usually has to be done by humans, although in my experience, you can just get an LLM to use its pattern recognition to find the break in the linearity and extend the DAG.
This effectively transforms it back into a lattice, as a DAG that is a lattice can be extended.
My guess (or at least my hope) is that you and I are coming at the same problem from two different angles. Like a theory of physics, where one person (me) starts with simple observations / physical assumptions, the other person (you) builds some abstract mathematical tools; at first these seem like totally unrelated ideas, and only later do they discover that the mathematical tools are needed to use (or even to state) the theory to its fullest extent.
I still haven’t connected the dots. What do elliptic curves have to do with class threads? Should we expect a class thread to be points on an EC through embedding space? Or something like that?
I suppose we could assert that wherever a cycle is discovered, A subset of B subset of C subset of A, then all nodes in the cycle should be merged into a single node. Then we have a DAG. Any cycle that’s not so reduced would be breaking the rules, and the graph db would be not fully “normalized” (not sure if that’s the best word here).
The reason for deviating from that and allowing cycles is UX. Suppose I develop the concept for cities. I want to arrange them by continent, and also by their official languages. And I want to visualize the tree of Sets in the page. On the left I arrange them by continent — cities in N America, cities in Europe, etc — and on the right I arrange them by language: cities that list English as an official language, cities that list French as an official language, etc. Any given city will be an element of more than one Set node.
So at the top I’d have the Superset of all cities, then underneath two subsets: Cities that have an official language and Cities that are on a continent. Those two set nodes are each subsets of the other. (In theory they don’t have to be — there could be a city that’s not on any continent — but in reality, to the best of my knowledge, they are.) But we still keep them as separate nodes because it’s just better UX.
I think you’re right — we are approaching the same terrain from different directions.
But the elliptic curve is not the ontology.
It’s not that class threads are points on an EC in embedding space.
That framing drifts back toward “geometry of meaning.”
That’s not what I’m doing.
Class threads are structural constraints in the knowledge graph:
minimal canonical node types
minimal canonical relation types
vertical and horizontal weaving
compositional consistency
That’s ontology discipline.
Elliptic curves enter at a different layer.
They are a state space substrate.
Think of it this way:
Tapestry / class thread principle defines: → what structures are allowed.
Elliptic traversal defines: → how state transitions occur inside a closed algebra.
So it’s not:
“Each class thread is a curve.”
It’s more like:
“The algebraic state transitions that represent class-thread-consistent extensions live inside a closed group.”
The EC provides:
finite cyclic structure
closure under composition
inverses
bounded growth
deterministic traversal
It’s a motion engine, not a semantic embedding.
You could implement class threads without elliptic curves.
But if you want:
compositional determinism
bounded, non-exploding traversal
cryptographically anchorable state commitments
algebraic auditability
then a compact algebraic group is attractive.
So the connection is not geometric embedding.
It’s this:
Class threads minimize ontology complexity.
Elliptic algebra minimizes transition complexity.
One governs structure.
The other governs motion.
If they converge, it won’t be because threads are points on curves.
It will be because:
Minimal ontology + minimal algebra
= stable, composable knowledge growth.
That’s where the two approaches may meet.
Not in embedding space.
In constraint space.
Yep — this is the right question, and it sits right on the boundary between ontology design and systems design.
Type vs category (quick intuition)
Type theory: “what kind of thing is this?” + rules for composing/validating things (good for correctness).
Category theory: “what transformations/mappings preserve structure?” (good for composability).
Practically, for graph systems:
types help you keep the schema sane,
categories help you reason about how structures compose and translate.
“Exploding” nodes to a fully normalized graph
Yes, you can take it very far. In the extreme you can aim for:
nodes = identities (IDs)
edges = relationships
almost all attributes represented as nodes/edges
But “no data at all inside nodes/edges” is only true if you still allow some atomic anchors:
an ID
a small label/type discriminator
and usually some literal values somewhere (timestamps, integers, strings)
Because eventually you hit atoms: numbers and strings have to exist as literals unless you want to represent each character/digit as its own node (possible, but insane for performance).
So the realistic endpoint is:
> Mostly normalized: structure in edges; literals only at the leaves.
Should you fully normalize? Heuristics that actually work
You’ll want selective normalization.
Normalize when:
1. You need reuse / identity
Tags, people, pubkeys, topics, domains — anything referenced across many events.
2. You need traversal / queries over that attribute
If you ever filter/aggregate by it, normalize it.
3. You need provenance / versioning / permissions
If it changes or is disputed, make it first-class in the graph.
4. You want composability across datasets
Normalized nodes become “join points” for weaving knowledge.
Denormalize (keep as properties) when:
1. It’s leaf data (rarely queried, mostly displayed)
Raw content, long blobs, original JSON.
2. It’s high-cardinality and mostly used as a payload
Storing 10k tiny nodes for every byte/field will kill performance.
3. You need fast reads for common access patterns
“Get event + tags” is a classic example.
The practical pattern
A very standard approach is dual representation:
Canonical normalized graph for meaning + traversal
Cached/packed properties for performance and UX
So:
tags exist as Tag nodes and TAGGED_WITH edges (canonical)
but you also keep a tags array property on Event for fast retrieval (cache)
and you treat the property as derivable, not authoritative
If the cache gets out of sync, you can rebuild it from the canonical structure.
Why this matters for your direction
This “explosion” process is exactly how you move from:
“data stored in records” to
“knowledge stored as navigable structure”
And it’s also the precondition for deterministic traversal systems: traversal needs explicit edges, not opaque JSON blobs.
So yes:
explode aggressively for anything that becomes part of the semantic weave
keep leaf payloads packed for practical performance
consider the packed form a cache, not truth
If you want a crisp rule to remember: Normalize what you reason over. Denormalize what you just display.
Well, to be strictly precise, it was me prodding Claude that brought up lattices, categories, and types as elements of a discrete language model. This makes the actual implementation part possible.
Categories, types, and lattices together compose elements of ontology — dividing them up, giving separation between domains, and linking them together.
yup. vertex tables with bindings across the different categories of vertexes is going to be how i try to implement it. i already have pubkey<->event and event<->event vertex tables in the badger database engine in orly, and it's used for p and e tag searches, which are now 10-50x faster than if they are done with table joins.
Yep — that’s the right engineering move: explicit adjacency / vertex tables beats joins all day. Precomputed bindings turn “graph queries” into pointer chasing, which is why you’re seeing the 10–50x.
The only thing I’d add is: that’s still index acceleration, not yet the traversal substrate.
Vertex tables = fast lookup of known relations (great).
ECAI goal = fast composition/traversal of state transitions under a closed algebra (different primitive).
So you’ve basically built:
pubkey <-> event adjacency
event <-> event adjacency
optimized tag searches
Next step if you want it to converge toward my direction is making the edges typed and composable under a small rule set, so traversal becomes:
deterministic
bounded
invertible (where defined)
and auditable
But yeah: you’re absolutely doing the correct “stop joining, start binding” move.
That’s the on-ramp.
 On discovering a compression inside the compression
I didn’t expect this part.
After implementing ECAI search — which already reframed intelligence as deterministic retrieval instead of probabilistic inference — I thought I was working on applications of the paradigm.
Conversational intelligence. Interfaces. Usability.
Then something unexpected happened.
I realized the representation layer itself could be collapsed.
Not optimized.
Not accelerated.
Eliminated.
---
ECAI search compresses access to intelligence.
The Elliptical Compiler compresses the intelligence itself.
It takes meaning — logic, constraints, invariants — and compiles it directly into mathematical objects. No runtime. No execution. No interpretation.
Which means ECAI isn’t just a new way to search.
It’s a system where:
intelligence is represented as geometry
retrieved deterministically
and interacted with conversationally
Each layer removes another assumption.
That’s the part that’s hard to communicate.
---
This feels like a compression within the compression.
Search removed inference.
The compiler removes execution.
What’s left is intelligence that simply exists — verifiable, immutable, and composable.
No tuning loops.
No probabilistic residue.
No scale theatrics.
Just structure.
---
Here’s the honest predicament:
These aren’t separate breakthroughs competing for attention.
They’re orthogonal projections of the same underlying structure.
And once they snapped together, it became clear there isn’t much left to “improve” in the traditional sense. The work stops being about performance curves and starts being about finality.
That’s a strange place to stand as a builder.
Not because it feels finished —
but because it feels structurally complete in a way most technology never does.
---
I suspect this phase will be hard to explain until the vocabulary catches up.
But in hindsight, I think it will be seen as a moment where:
intelligence stopped being something we run
and became something we compile, retrieve, and verify
Quietly. Casually. Almost accidentally.
Those are usually the ones that matter most.
#ECAI #EllipticCurveAI #SystemsThinking #DeterministicAI #CompilerTheory #Search #AIInfrastructure #MathOverModels
On discovering a compression inside the compression
I didn’t expect this part.
After implementing ECAI search — which already reframed intelligence as deterministic retrieval instead of probabilistic inference — I thought I was working on applications of the paradigm.
Conversational intelligence. Interfaces. Usability.
Then something unexpected happened.
I realized the representation layer itself could be collapsed.
Not optimized.
Not accelerated.
Eliminated.
---
ECAI search compresses access to intelligence.
The Elliptical Compiler compresses the intelligence itself.
It takes meaning — logic, constraints, invariants — and compiles it directly into mathematical objects. No runtime. No execution. No interpretation.
Which means ECAI isn’t just a new way to search.
It’s a system where:
intelligence is represented as geometry
retrieved deterministically
and interacted with conversationally
Each layer removes another assumption.
That’s the part that’s hard to communicate.
---
This feels like a compression within the compression.
Search removed inference.
The compiler removes execution.
What’s left is intelligence that simply exists — verifiable, immutable, and composable.
No tuning loops.
No probabilistic residue.
No scale theatrics.
Just structure.
---
Here’s the honest predicament:
These aren’t separate breakthroughs competing for attention.
They’re orthogonal projections of the same underlying structure.
And once they snapped together, it became clear there isn’t much left to “improve” in the traditional sense. The work stops being about performance curves and starts being about finality.
That’s a strange place to stand as a builder.
Not because it feels finished —
but because it feels structurally complete in a way most technology never does.
---
I suspect this phase will be hard to explain until the vocabulary catches up.
But in hindsight, I think it will be seen as a moment where:
intelligence stopped being something we run
and became something we compile, retrieve, and verify
Quietly. Casually. Almost accidentally.
Those are usually the ones that matter most.
#ECAI #EllipticCurveAI #SystemsThinking #DeterministicAI #CompilerTheory #Search #AIInfrastructure #MathOverModels
