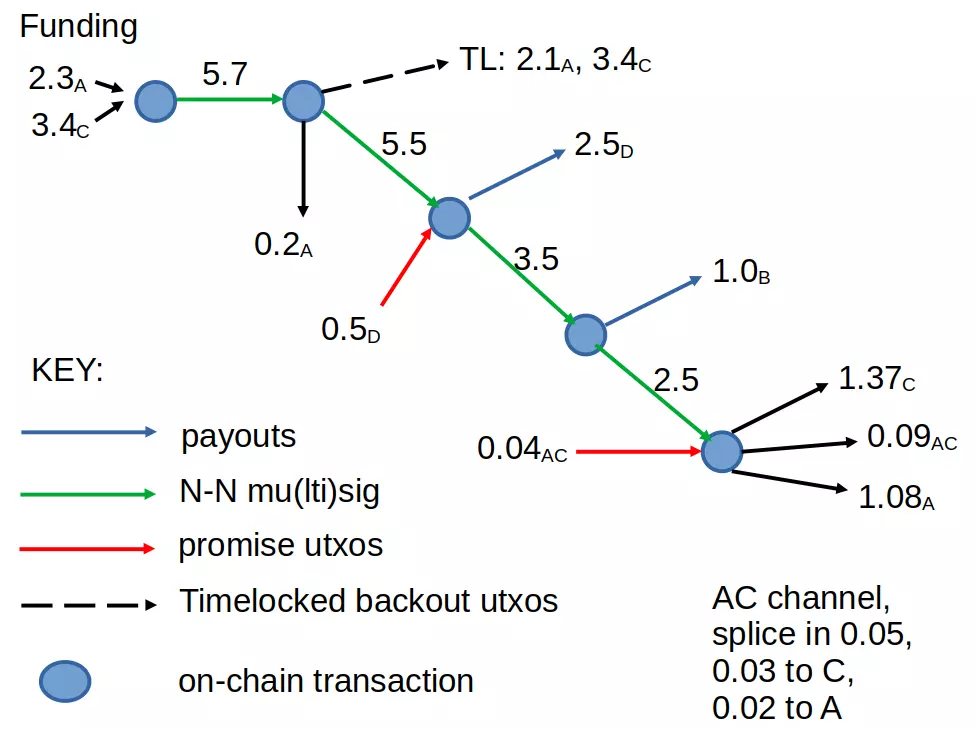
Replies (30)
I am working on some tools that needed to be able to insert & extract data from a closed web app. I wrote an extension and local server that has SSE APIs that allow the tool (native code app) and a chrome extension that can also talk to the local server via SSE / event sink and provide to the native app a pseudo “open” API. Works really well, the web app that it talks to has no idea it’s not a human pushing and pulling data. To be more clear, the server is embedded inside the native app.
The primary issue in my mind is that the api-s don't follow one well-defined standard, like signed Nostr events queried with filters.
This way you don't have to keep rewriting interfaces, and all data is verfiable.
The "closed" part is tricky: Even with wide-spread Nostr adoption I don't think that we would have completely free access to data.
Data is precious and people will protect it with digital fences, even if everything is signed and standardized.
But to the degree everything is interoperable and verifiable, we are in a very good place.
Even small backups can help in a major way. Real censorship becomes too costly in practice even for a large player.
It will result in more competition and therefore more openness as well.
Back in the days with all the open APIs there was a website with mashables / mashups. That’s something we can do again with Nostr.
Mashup (web application hybrid) - Wikipedia
Yahoo (of all companies) had an amazing tool called Pipes which facilitated mashing data. Way ahead of its time.

The one standard is absolutely not a problem - this is exactly what LLMs excel at.
If you tell it to use the OpenLibrary API, or OpenStreetMaps API, it will do it perfectly, because these APIs don't require authentication. These integrations feel absolutely magical.
Missing thing there was the money... We now have money 😉
Whilst the docs suggest it’s both paid and authenticated,
@Kagi have been quite nostr friendly so far
Search API | Kagi's Docs
Kagi Search Help
I believe
@rabble was actually involved/made this
Both APIs you mention live off donations. This is not really feasible for the whole internet.
Furthermore, they still apply rate limiting and such to not be abused. What if I want to run a service that puts heavy load on the that api but am ready to pay for it?
IP based rate limiting is a primitive technique compared to what Nostr offers.
If you want curated data sustainably you will need authentication and you are better off with a paid service beyond a threshold for sure.
If on the other hand some successful service goes rogue you will have much better guarantees to fork that service and jailbreak the data, if it uses signed and standardized Nostr events.
Otherwise your left with unverifiable data that only makes sense in a proprietary format that no one else uses.
That's exactly what Lightning excels at.
So what are you saying? Massive DDOS party?
if you want the AI to just slack of hard work done by youtube then sure your example is valid
now if all you have is many petabytes of raw unindexed data then no LLM will ever be able to create anything useful
Exactly. The web being closed is the bottleneck; open APIs would unleash a creative explosion like nothing we’ve seen. Nostr shows the future: decentralized, open, unstoppable.
Yup. Same thing killed the potential of grease monkey in the 00s.
Great opportunity for
@Kagi to seize.
you're making the black hats wet rn
But you must pay to use Kagi. I've never need to pay to search on the web since the early 2000s.
This is the strongest counter argument I’ve ever heard to the idea that capitalism breeds innovation
View quoted note →I don’t think we need another addition to the standard protocols.
View quoted note →Yep, I worked on Yahoo Pipes as the project I did right after leaving Odeo(ne twitter)... Mostly my work was on unit and integration tests in prep for launch as I joined it late. It was cool, yahoo killed it... we could totally bring it back and make something amazing that was pipes meets nostr.
Pipes2 lfg
you could use selenium if it does not need to be efficient
People, for "vIbE cOdInG" tend to use models which are not under their control (if it's not available for download under an open source license it's not under your control) and the training data and procedures of which aren't publicly known.
Therefore, nothing they do is under their control.
No, Nostr be like "here's 5000 *links* to videos, some of which on YouTube, some of which on some HTTP server and some of which unavailable".
Nostr works because hosting relays is cheap.
Hosting relays is cheap because they don't store videos, audio or images and they don't have full-text search functionalities.
If a lot of storage or computational power is required, you need to figure out a way to effectively minimize it, pay for it and rate-limit it.
The law applies even if you use Nostr.
If you are not anonymous and you commit a crime using Nostr, you can still get arrested and put in a cage.
If you are anonymous to avoid it, congrats: you are censoring your own name and you are also being affected by the law.
> vibe coders could query it permissionless
They would send the kind of queries that the Nostr protocol allows for, which are nowhere near enough for a fully-fledged search engine.
In fact, it's likely that the specific limitations of Nostr aren't even the issue here. Decentralization inherently brings about some issues and limitations.
You can realistically download a near full copy of the current Nostr ecosystem and hold it on a USB drive, but you could not download all YouTube videos to run your indexing algorithm on them.
Yes, but you can't run full search.
YouTube has access to the full content on videos, to subtitles, to semantic annotation, to user feedback. To a lot of stuff you need to make it an effective search engine. And even if you had all that data, and where to store it, you would still need the computational capacity for doing so.
> but the *discovery* game? different story.
Currently one of the most typical feedback from new Nostr users is how much it utterly sucks for discovery.
My typical answer is that Nostr isn't bad, it just doesn't address discovery (the problem it does solve is retaining your audience without any company being able to censor you, which is a different problem).
> show me videos where 10+ privacy nerds i follow all zapped the same link
That's already a non-trivial query. You can't run this directly against relays through the Nostr protocol.
Of course if you download all Nostr data first, then you can do whatever you want.
>What if I want to run a service that puts heavy load on the that api but am ready to pay for it?
That's not how it works. You point your client directly at the API, so the user's IP is the one hitting it.
Sure, in your case because you designed it that way.
I can imagine a service that queries some data from another service as _part_ of the end result, but the user is hitting your endpoint.
Anyway, what you *can* do with nostr is hitting any service with *any* pubkey - meaning you can decide to pay for your users or make your users pay for it directly, or some other clever combination.
IP addresses don't give you that freedom - it is not a good idea to use them as identity on the internet, so you see most paid services requiring an account.
Nostr could be that account.